
“La deduplicación de datos (Data Deduplication) es una técnica que se emplea en soluciones analíticas para eliminar datos duplicados dentro de un conjunto de información, optimizando así recursos, espacio de almacenamiento y eficiencia en los procesos analíticos. El proceso automatizado identifica bloques o registros redundantes y los elimina, reemplazando las duplicidades con referencias al dato original, asegurando que los análisis, informes y modelos produzcan resultados más precisos y fiables”.
La Deduplicación de Datos a vista de pájaro
Todos los recursos que los seres humanos buscan utilizar con fines o propósitos avanzados (petróleo, metal, agua…) deben procesarse de alguna manera antes de poder transformarse en una forma nueva y más valiosa.
El recurso más preciado y novedoso de nuestros tiempos, los datos, no es una excepción. Departamentos de TI enteros y equipos de ingenieros de datos cualificados se encargan cada día de esta importante tarea, dedicando horas de su tiempo (otro recurso muy preciado) a montar canalizaciones de datos para introducirlos en plataformas de BI y ciencia de datos, de forma que puedan utilizarse para tomar decisiones. Esto implica limpiar los datos y prepararlos para los analistas, los usuarios de las unidades de negocio, los desarrolladores, los científicos de datos e incluso los clientes que acceden a sus propios datos a través de análisis internos integrados en productos y aplicaciones digitales.
Todos los procesos de fabricación avanzados desarrollan herramientas especializadas que realizan funciones específicas orientadas a optimizar la cadena de producción y, en el ámbito de la analítica, las herramientas más avanzadas para este propósito son el aprendizaje automático (ML) y la Inteligencia Artificial. Estos potentes sistemas pueden utilizarse para ayudar a los ingenieros de datos y a cualquier otra persona involucrada en la preparación de datos a simplificar su trabajo mediante la automatización de tareas repetitivas a gran escala.
Una de las mayores aplicaciones de la IA, el ML y la analítica aumentada es, precisamente, ayudar en el ámbito de la deduplicación de datos (Data Deduplication).
Algoritmos de aprendizaje automático
La IA usa algoritmos de aprendizaje automático para escanear y comparar bloques o registros de datos, detectando duplicados con gran precisión, incluso con variaciones menores o en diferentes formatos.
Aprendizaje por refuerzo
Mediante aprendizaje por refuerzo (Reinforcement Learning), la IA ajusta sus criterios para separar o fusionar registros, optimizando continuamente la efectividad del proceso de deduplicación.
Combinación de múltiples modelos
La IA puede combinar múltiples modelos para garantizar una mayor exactitud y reducir falsos positivos en la eliminación de duplicados.
Reducción de la carga manual mediante la automatización
La IA puede disminuir la necesidad de intervención manual, agilizar las operaciones y manejar grandes volúmenes de datos en entornos distribuidos con alta eficiencia.
Y como su nombre indica, la deduplicación de datos es el proceso de eliminar datos redundantes de un conjunto de datos, lo que puede ayudar a crear un conjunto de datos más coherente o a reducir la dimensionalidad. Una herramienta de deduplicación de datos tiene muchas partes móviles y puede aportar una compleja gama de potencia informática y asistencia a un conjunto básico de datos.
¿Por qué es tan relevante para el análisis de datos?
Según Forbes, el 80 % del trabajo de los científicos de datos consiste en la preparación de datos, y el 76 % de los encuestados afirmó que era la tarea que menos les gustaba. Estas razones ya serían suficientes para hacer lo que fuera necesario para automatizar estos procesos. Los expertos en datos (ingenieros, científicos, equipos de TI, etc.) que se encargan de la preparación de datos están más interesados en conectarse a fuentes de datos, crear canales estables y otras tareas más complejas. Obligarlos a realizar tareas rutinarias y tediosas, como la preparación de datos, reduce su motivación y les aleja del trabajo de mayor valor que podrían estar realizando en beneficio de la empresa.
Debemos tener en cuenta que una deduplicación de datos adecuada tendrá un gran impacto en los resultados de una empresa, y a pesar del incremento de las fuentes en la nube que las empresas deben procesar ha coincidido con una reducción de los costes por unidad de los datos almacenados, sigue habiendo costes asociados al mantenimiento de los volúmenes de datos; y la duplicación de datos aumenta esos costes. Los datos adicionales también pueden ralentizar los tiempos de respuesta de las consultas, lo que retrasa la toma de decisiones. Además, los datos duplicados pueden devolver resultados falsos que conduzcan a decisiones empresariales incorrectas. En el acelerado entorno empresarial actual, los retrasos y errores como estos son muy costosos. La proliferación de tipos y ubicaciones de almacenamiento de datos introduce una nueva gama de errores asociados.
Para mitigar este riesgo, la deduplicación es un paso fundamental en el proceso de limpieza de datos. Eliminar la información duplicada, ya sea dentro de una base de datos individual o como parte de un modelo de datos (con un depurador de deduplicación u otra herramienta de propósito similar), es clave para garantizar resultados precisos para los análisis e informes.
Por tanto, la deduplicación de datos es tan relevante para el análisis de datos porque los datos duplicados o inconsistentes distorsionan los resultados, inflan las métricas y generan decisiones erróneas, mientras que la deduplicación asegura que el análisis refleje la realidad del negocio, aumentando la precisión, la eficiencia y la confianza en los insights.
Los duplicados distorsionan los resultados
- Inflación de métricas: Por ejemplo, si un cliente aparece dos veces en la base de datos, las métricas de clientes activos o ventas por cliente se duplican, dando una visión falsa de crecimiento o penetración de mercado.
- Informes inconsistentes: Diferentes áreas de la empresa pueden generar reportes que no coinciden entre sí porque dependen de registros duplicados.
- Impacto en predicciones: Modelos de ML entrenados con datos duplicados tienden a sobreestimar patrones, produciendo predicciones sesgadas o menos confiables.
En resumen: sin deduplicación, los análisis están contaminados desde la base, y cualquier insight se vuelve sospechoso.
Mejora la precisión del análisis
- Datos únicos y consistentes: Cada entidad (cliente, producto, transacción) se representa una sola vez, evitando errores al contar, agrupar o comparar.
- Confianza en los KPIs: Los dashboards muestran métricas que reflejan la realidad, lo que permite decisiones más certeras y rápidas.
- Facilita segmentación y personalización: Al eliminar duplicados, se puede hacer marketing, ventas y operaciones basadas en datos verdaderos, sin enviar ofertas repetidas a los mismos clientes.
En resumen: la deduplicación es la base de un análisis confiable y útil para la estrategia del negocio.
Incrementa la eficiencia y la escalabilidad
- Menos almacenamiento y procesamiento: Datos duplicados ocupan espacio innecesario y ralentizan consultas y cálculos.
- Optimización de recursos: Los equipos de análisis pasan menos tiempo limpiando datos y más tiempo generando insights accionables.
- Preparación para crecimiento: A medida que el volumen de datos aumenta, una base limpia permite escalar análisis y BI sin problemas, incluso con millones de registros.
En resumen: depurar datos no solo mejora la calidad, sino que hace que el análisis sea más rápido, escalable y rentable.
A continuación, veamos cómo se realiza la deduplicación con un algoritmo de aprendizaje automático (ML).
Deduplicación de Datos mediante algoritmo ML
Una de las formas más comunes de implementar una herramienta de deduplicación en una plataforma de BI es agregar datos a lo largo de una determinada dimensión para realizar análisis. En muchos casos, los datos provienen de diversas plataformas (diferentes bases de datos en la nube, sistemas de software como Salesforce, etc.) y la misma información puede representarse de forma diferente, lo que produce agregaciones de datos engañosas que podrían llevar a conclusiones erróneas. La deduplicación detecta diferentes instancias de la misma información y aplica automáticamente la lógica para garantizar una entrada uniforme como parte de la transformación de datos.
La corrección de cadenas forma parte de muchos procesos de incorporación de datos. El personal de los equipos de BI dedica mucho tiempo a agrupar y sustituir manualmente los datos redundantes, a veces utilizando búsquedas con diccionarios predefinidos generados a partir de la experiencia personal o departamental. Otra opción es utilizar sentencias SQL CASE personalizadas, como por ejemplo:
case [Nombre] cuando “John Smith” entonces “J. Smith” case [País] cuando “Afrika” entonces “África”
El proceso manual para corregir estas duplicaciones puede ser lento, frustrante y propenso a errores. Sin embargo, una opción más avanzada para acelerar y automatizar este proceso es utilizar ML. El algoritmo adecuado puede manejar estas tareas rápidamente y ayudar a construir un conjunto de datos limpio, listo para la producción de cuadros de mando.
Veamos cómo funciona:
Al ejecutar la deduplicación con un algoritmo, el sistema toma una columna de datos determinada y la divide en un grupo de información (clústeres) que se relacionan con un único atributo (un atributo que tiene el mismo significado, que puede ser propiedades fonéticas, distancia, etc.). A continuación, el algoritmo permite al usuario definir el atributo deseado por grupo (frecuencia de aparición en el clúster, etc.). La primera vez que el sistema analiza una columna, el usuario elige cómo se comporta y cuán inclusivos deben ser los resultados. Una vez que el algoritmo ha hecho su trabajo, la información final se puede utilizar en el panel de control para análisis como un campo normal. ¡Fácil!
Los sistemas de BI con este tipo de funcionalidad, como Sisense, son capaces de analizar y agrupar datos de un modelo de datos a nivel de columna. Esto significa que el modelo examina cada columna, identifica cadenas similares y las agrupa en un único valor, de la siguiente manera:
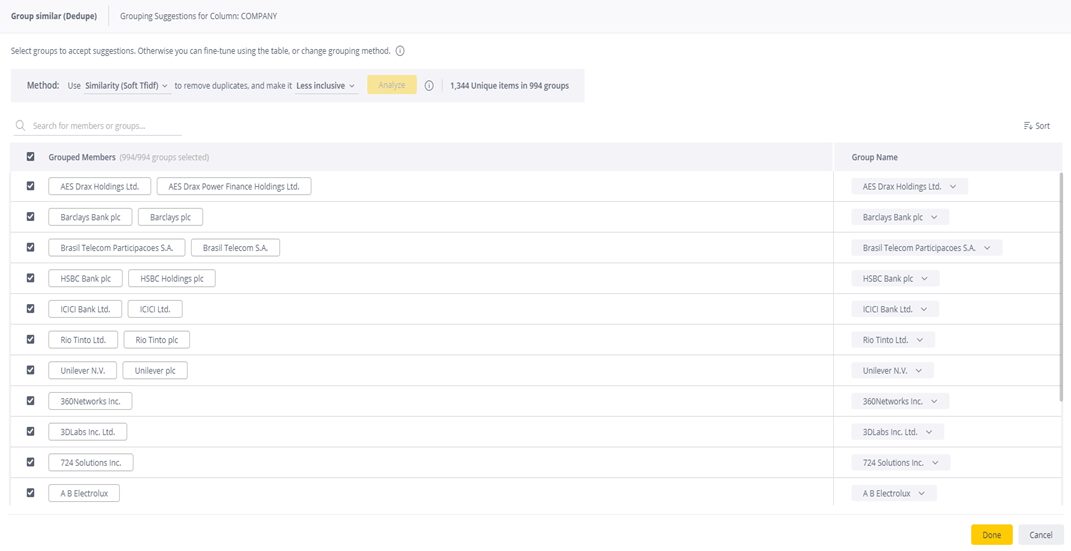
Veamos a continuación tres métodos para analizar datos basados en funciones de similitud:
Similitud en cadenas de texto
El sistema aplica un algoritmo TFIDF (Frecuencia del término-frecuencia inversa del documento) suave en el que las cadenas similares se agrupan por rango. Los términos que aparecen con demasiada frecuencia, como «empresa» e «inc», reciben una puntuación más baja, ya que son cadenas menos únicas.
Similitud ortográfica
Es especialmente útil cuando hay errores tipográficos, variaciones de nombres o formatos distintos: este método agrupa cadenas similares en ortografía.
Similitud fonética
Este método agrupa términos que suenan similares, por ejemplo, cadenas que utilizan «f» o «ph».
Al utilizar una herramienta de BI como Sisense, con funciones de deduplicación mediante IA, es necesario probar cada método para encontrar los resultados que mejor se adaptan a las necesidades de tu organización, ajustando el nivel de inclusividad o granularidad hasta crear un conjunto de datos que se ajuste a tus requerimientos.
La mayoría de los sistemas están configurados en un nivel predeterminado que es menos inclusivo, lo que significa que los resultados son más precisos. Cuanto más inclusivos sean los resultados, menor será la precisión. Si los resultados son demasiado inclusivos, es posible que tengas que dedicar tiempo a editar los resultados que no se ajustan a tus necesidades. Ninguna herramienta de deduplicación es perfecta, especialmente la primera vez que se utiliza.
IA y Datos: Posibilidades
El aprendizaje automático y la IA tienen capacidades más amplias para limpiar datos, más allá de actuar como un sofisticado depurador de deduplicación. Una vez más: cualquier tarea rutinaria realizada por humanos puede ser realizada por un algoritmo entrenado en un sistema de IA. Pueden limpiar y estandarizar los datos a medida que se mueven, extraen y cargan, e incluso detectar valores atípicos en el conjunto de datos y alertar a los usuarios (humanos).
En primer lugar: estandarizar los datos. Es más fácil analizar y trabajar con datos que tienen un formato similar. Por ejemplo, se puede entrenar a un sistema de IA para que examine un conjunto de datos y convierta todas las entradas a minúsculas (a menudo el formato preferido para escribir consultas). Eliminar los espacios erróneos antes o después de las entradas es otra práctica de estandarización útil, ya que las herramientas de BI pueden ser muy literales al responder a las solicitudes de consulta. Por ejemplo, «usuarios» para un humano no es lo mismo que «usuarios» para un ordenador, por lo que el análisis de esas dos entradas arrojará resultados incorrectos. En lugar de dedicar horas de trabajo humano a revisar los datos, la IA puede encargarse de estas tareas repetitivas con facilidad y ofrecer un conjunto de datos más limpio.
Actualmente, las organizaciones manejan datos en una amplia variedad de ubicaciones y múltiples bases de datos en la nube, por lo que es imprescindible cargarlos todos en una herramienta central de BI. Este es otro ámbito en el que la IA puede ayudar, escaneando y sugiriendo acciones de limpieza mientras se transfieren los datos. Además de actuar como herramienta de deduplicación, la IA también puede rellenar valores en blanco y garantizar que el producto final esté listo para ser analizado. Dependiendo del conjunto de datos de entrenamiento, la IA también puede ofrecer a los usuarios humanos opciones adicionales para mejorar la calidad del nuevo conjunto de datos.
La detección de valores atípicos es una tarea clásica de la IA. Dado que los algoritmos son buenos para el reconocimiento de patrones, también son buenos para detectar valores que se salen de los resultados esperados. Cuando un sistema escanea el conjunto de datos, básicamente se pregunta «¿Esta columna parece correcta?» y comprueba aspectos como los valores aceptados, los valores nulos, los valores atípicos numéricos, la unicidad (por ejemplo, cada usuario debe tener su propio user_id, etc.) y la integridad referencial (para los valores que son claves de diferentes tablas). Cuando la IA se encuentra con un valor que no tiene sentido con lo que se le ha enseñado a esperar, puede mostrar ese resultado erróneo a los usuarios humanos, que pueden tomar medidas al respecto.
Estas son solo algunas de las formas en que los sistemas de IA podrían ayudar algún día a los ingenieros de datos y a todos los usuarios a sacar más partido a sus datos y dedicar menos tiempo a los procesos manuales (pero necesarios) de limpieza de datos.
La IA y los ingenieros: socios en la construcción del futuro
No deberíamos olvidar un hecho: ¡El futuro se está construyendo sobre la base de los datos en este mismo momento! Ese futuro agrupará innumerables conjuntos de datos procedentes de fuentes en la nube, en las aplicaciones y en cualquier otro lugar en el que los creadores recopilen y almacenen datos. Dependerá de los ingenieros de datos construir canales duraderos y estables que proporcionen esos valiosos datos a las herramientas de BI y permitan a los analistas, usuarios y clientes sacarles el máximo partido.
Esos intrépidos ingenieros no estarán solos. El futuro se construirá sobre datos y estará impulsado por la analítica aumentada. Los sistemas de inteligencia artificial integrados en las potentes plataformas de análisis del futuro limpiarán y prepararán los datos a medida que se introduzcan en la plataforma. Estos sistemas eliminarán los molestos datos duplicados, rellenarán los valores nulos, identificarán los valores atípicos, sugerirán uniones e incluso guiarán a los usuarios humanos para que encuentren nuevos conocimientos que quizá nunca hubieran identificado por sí mismos.
Sisense está liderando el camino hacia esta nueva era con potentes componentes de aprendizaje automático e inteligencia artificial que facilitan la vida a los ingenieros de datos y a todas las personas involucradas en el proceso de BI.
Y tienes la ocasión de comprobar por ti mismo lo que Sisense puede hacer por tu organización para construir el futuro de tu empresa sobre una plataforma lo suficientemente potente como para manejar cualquier cosa que tu imaginación pueda plantearte.
¿Quieres saber cómo Sisense puede ayudarte a mejorar la calidad y la limpieza de datos a través de un proceso de deduplicación eficiente, asistido por la IA, de forma que cada decisión futura se base en información única, confiable y accionable, convirtiendo los datos en una ventaja competitiva real?
Hablemos, te mostraremos cómo es posible hacerlo realidad viendo Sisense en acción.
Parapentex Studios, July 2025