Una respuesta innovadora: Sisense y su modelo In-Chip technology lidera la innovación ofreciendo un rendimiento máximo en las analíticas avanzadas
Una de las principales causas del fracaso de las iniciativas analíticas en muchas organizaciones tiene una relación directa con los deficientes tiempos de respuesta que el sistema analítico proporciona al analista de negocio que, en muchos casos, no cuenta con los mismos recursos que los equipos de IT.
Conscientes de esta problemática, los equipos de ingeniería de Sisense han puesto el foco en garantizar el máximo rendimiento de los sistemas analíticos aprovechando, de forma eficiente, toda la pila de recursos que la tecnología ofrece actualmente, desde el procesador a la memoria pasando por los dispositivos de almacenamiento; una estrategia que es única con respecto a sus competidores.
Con la tecnología In-Chip, Sisense se posiciona como líder en innovación al ofrecer a sus clientes tiempos de respuesta en todos los contextos analíticos donde es posible implementar su tecnología.
Una perspectiva histórica del rendimiento de los sistemas analíticos: OLAP y sus limitaciones en el panorama analítico actual
El origen de las necesidades analíticas y los elementos vinculados al bajo rendimiento se remonta a los sistemas OLTP, un modelo que ofrecía soluciones de reporting sobre bases de datos relacionales (en el mejor de los casos). La creciente necesidad de facilitar respuestas más elaboradas y la capacidad de la tecnología para visualizar en forma de KPIs información precisa del seguimiento del negocio, dio origen, de forma muy exitosa, a la implantación de sistemas de data warehousing.
Con el fin de centralizar e integrar los datos corporativos para cruzar información de diferentes sistemas (la mayor parte internos), pero con la vista puesta en el rendimiento que un modelo relacional no podía ofrecer, los sistemas OLAP (ROLAP, MOLAP) se presentaron como la respuesta más eficaz para dar soporte a los desafíos que la tecnología ofrecía en aquellos momentos. Sin embargo, se ha demostrado que los sistemas de data warehousing no encajan con el movimiento agile & lean enterprise actual y la necesidad de ofrecer mayor autonomía a los equipos de analistas de datos, dado que solo proporcionan respuestas a un conjunto de preguntas muy limitado y, cualquier cambio, en el peor de los casos, implica el diseño de nuevas estructuras de datos y los necesarios procesos de carga de las mismas. Debemos tener en cuenta que los procesos ETL impactan en el 70% del tiempo y el esfuerzo que es necesario realizar para preparar cualquier modelo analítico, sin ofrecer al analista de negocio una visualización inmediata de los resultados; una gran limitación si pretendemos ofrecer autonomía y capacidad de autoservicio a nuestros equipos de negocio. Por otra parte, exige, en la mayoría de los casos, la intervención imperativa de las áreas de sistemas o la contratación de terceros para realizar estas labores, algo que termina dinamitando precisamente ese objetivo: la autonomía y el autoservicio como funciones estratégicas inherentes al objetivo de democratización del uso de los datos.
El resultado son sistemas tremendamente encorsetados y con poca capacidad real de cambio; no digamos para cambiar los comportamientos. Además, el rendimiento de las consultas contra estos sistemas depende de estructuras complementarias ––índices, tablas resumen, entre otros–– que cargan y complican lo que debería ser un modelo multidimensional simple y de acceso universal. Las iniciativas OLAP en la actualidad se utilizan sobre soluciones departamentales ––como pueden ser iniciativas EPM–– que abanderan el acceso directo por parte del analista a los datos, lo cual es real en un cierto sentido, pero que exige un diseño previo de los cubos por parte de las áreas de IT, precisamente porque dan respuesta a un conjunto de consultas que previamente se han debido identificar y no a un entorno de cambio con el que se convive en el contexto analítico.
La tecnología OLAP era la solución adecuada en un escenario de costes altos de tecnología y aplicaciones acotadas, tanto en las fuentes de datos como en el uso y la explotación de un conjunto acotado y predefinido de indicadores. Los cubos OLAP almacenan las respuestas a las preguntas más frecuentes en hojas de datos a las que se accede a través de las dimensiones específicas que el analista contempla, y es entonces cuando se realiza un uso intensivo de la CPU del servidor para realizar las agregaciones y presentar los datos.
La respuesta a las carencias de OLAP: In-Memory Database
Frente al crecimiento exponencial de los volúmenes de datos, la aparición de fuentes de datos externas de información no estructurada pero muy valiosa para el negocio, junto con la demanda de mejores tiempos de respuesta, la solución tecnológica que proporcionaba un abaratamiento de los dispositivos de memoria fue la tecnología In-Memory Database. Sus pilares son la reorganización de la información proveniente de los data warehouse corporativos en bases de datos columnares cargadas íntegramente en memoria. Este diseño elimina el uso de estructuras complementarias para mejorar el rendimiento y las pesadas agregaciones de datos que los sistemas OLAP deben llevar a cabo con un uso intensivo de la CPU. La información reside en memoria, con lo que el tiempo de respuesta disminuye drásticamente, y el mantenimiento de estas soluciones se simplifica al no tener que gestionar estructuras adicionales a los datos del negocio. Además, al disponer de la información en memoria, el paso que se debía dar para subir a la RAM aquellas tablas sobre las que se hacía scan se ahorra drásticamente. Esta solución lo basa todo en las estructuras de memoria, descartando los dispositivos de almacenamiento.
Sin embrago, la realidad es que 1GB de disco es del orden de un 320% más económico que 1GB de RAM. Además, la realidad hoy en día es que el crecimiento en los volúmenes de datos es exponencial, por lo que las iniciativas In-Memory no son eficaces para liderar estrategias de datos transversales a la organización, y terminan, como OLAP, bien en soluciones departamentales, bien en soluciones de alcance acotado. Esta inviabilidad viene dada porque el crecimiento exponencial de los datos no está acompañado de una reducción y ajuste en el precio de los dispositivos de memoria. Esto implica que, al manejar un entorno de recursos muy acotado, generalmente las organizaciones tienen que optar por definir qué estructuras formarán parte de las bases de datos In-Memory, descartando otras.
Volvemos en este punto a, como mínimo, aumentar las tareas de mantenimiento por parte de las áreas de IT para que en todo momento los analistas de negocio tengan disponible la información que precisan. Y en el peor de los casos, necesidades de mayor inversión para resultados, insistimos, acotados.
La innovación en entornos complejos de datos: In-Chip Technology
En este punto, Sisense ha desarrollado la tecnología In-Chip para hacer un uso intensivo de todos los recursos que los sistemas ofrecen, y no solo de los dispositivos de memoria, ofreciendo toda la flexibilidad que los sistemas OLAP no pueden ofrecer, así como en la práctica muchas iniciativas In-Memory, junto con la reducción de costes que la tecnología In-Memory no puede ofrecer, asegurando un rendimiento extremo sobre cualquier acceso que el analista de negocio requiera de sus datos. Además, In-Chip funciona sobre cualquier tipo de hardware, por lo que no requiere de componentes propietarios: ni software, como sistemas operativos, ni hardware. Muchos fabricantes en la actualidad ofrecen appliances hardware como respuesta al despliegue de sus soluciones software de Business Intelligence. Esto hace que se manejen entornos cerrados propietarios a costes muy elevados con el único objeto de garantizar un tiempo de respuesta aceptable.
In-Chip no requiere hardware propietario para su desempeño. Se basa en una base de datos columnar en disco, aprovechando los tiempos de acceso que las bases de datos columnares ofrecen, que son nativas en Sisense Elasticube. Las consultas se resuelven enteramente en memoria sin lecturas en disco, que son una de las fuentes de bajo rendimiento y, lo más importante, solo un subconjunto de datos reside en memoria RAM en cualquier momento, dotando de mayor espacio para operaciones que se deben acometer en paralelo. Por tanto, desaparece la limitación por el tamaño de la RAM de los equipos.
Esto se consigue con unos algoritmos de compresión avanzada aplicados sobre la base de datos columnar, junto con la identificación inteligente de datos que no son usados regularmente y que puede marcarse como en un estado latente (cerca del 80% de los datos). La forma en cómo In-Chip gestiona los joins, mediante álgebra columnar en lugar de enlaces de tablas, estas operaciones, que son el foco principal de las demoras en el acceso a los datos, se pueden procesar completamente en la cache de las CPUs de los equipos. In-Chip optimiza aún más el procesamiento de datos aprovechando al máximo todos los recursos que las arquitecturas actuales de 64 bit ofrecen. Usando algoritmos propios que trabajan por debajo del sistema operativo y reemplaza su conjunto de instrucciones, se optimiza al máximo el uso de la CPU, logrando tiempos de respuesta sin precedentes. Este código propio evita fallos de cache reduciendo al máximo la copia de bloques de datos entre la RAM y la CPU.
Cómo trabaja In-Chip Technology
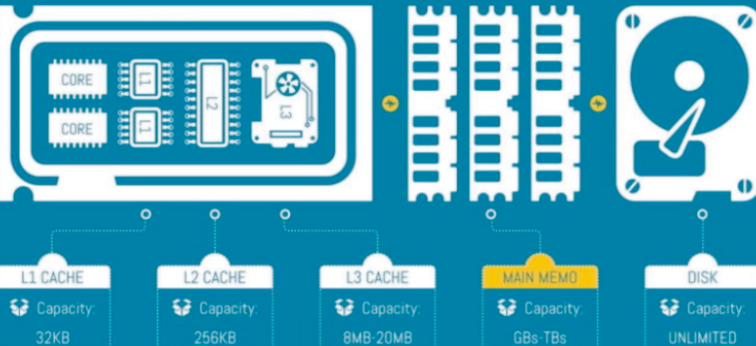
Debemos tener en cuenta que las CPU’s de hoy son extremadamente potentes y tienen cachés relativamente grandes: una CPU x86 tiene tres capas de memoria en el chip, donde los datos se almacenan antes de ser procesados, las caches L1, L2 y L3. Cada core de CPU tiene una cache dedicada L1 y L2, mientras que la caché L3 se comparte entre todos los núcleos. El caché L1 tiene una capacidad de 32KB, 256KB el caché L2 y el L3 entre 8MB y 20MB. Toma 3 veces más tiempo para que un core de CPU recoja los datos de la caché L1 que los datos que ya están en el core. Si los datos están en L2, unas 3,3 veces más por lo que se tarda unas 10 veces en extraer los datos de la caché L2. Si están en L3, se tarda 3,5 veces más, totalizando 35 veces en tiempo. Los datos en RAM son 10 veces más lentos, y en disco, miles.
In-Chip considera las especificaciones de la CPU y aplica su código para organizar los datos de la consulta y comunicarlos a la CPU de forma que, si ésta los necesitara nuevamente, ya existirían en su caché.
In-Chip aprende a buscar los conjuntos de resultados comprimidos asociados de antemano, con los resultados de sub-consulta precargados en la caché L1 como datos comprimidos, haciendo uso extremadamente económico de este recurso muy rápido pero limitado. Posteriormente, las imágenes descomprimidas de esos mismos datos se pueden mover a las cachés L2 y L3 más lentas pero mayores. De esta forma, las operaciones de compresión y descompresión leen y escriben en caché, y por tanto son extremadamente rápidas.
In-Chip también se centra en sacar mayor provecho de las CPU multicore. Cuando se procesan consultas o se realizan cálculos analíticos, se aplica álgebra vectorial a los datos, lo que permite la explotación completa de las instrucciones SIMD x86 (In-Chip Single Instruction Multiple Data), también llamadas instrucciones vectoriales. Esto permite que las instrucciones de CPU actúen sobre las columnas de datos. Por este motivo, los cores de CPU procesan los datos mucho más rápidamente porque procesan muchos valores en paralelo.
In-Chip hace un uso intensivo de disco, usando la base de datos columnar que se gestiona desde Sisense Elasticube. In-Chip solo carga en memoria las partes de datos que son requeridas por una consulta en tiempo real. Al trabajar con una base de datos columnar, el volumen de datos es drásticamente inferior a una base de datos que almacena registros. Esto permite a In-Chip escanear un campo de una tabla sin tener que hacer un scan de toda la tabla. También facilita la compresión, lo que ahorra espacio de almacenamiento, a lo que In-Chip suma la capacidad de realizar cálculos en conjuntos de datos comprimidos. Esto implica el uso de RAM de volúmenes de datos que se extienden más allá del tamaño de RAM física.
Finalmente, con el uso de álgebra columnar, permite que una consulta se desglose en miles de instrucciones de álgebra columnar que el motor In-Chip puede reutilizar sin volver a calcular a través de diferentes consultas con planes de ejecución similares. Esto se traduce en que la ejecución de una consulta mejora el rendimiento de otra consulta diferente, a diferencia de un caché estándar que almacena resultados. Esto implica también que un usuario concurrente agrega muy poca sobrecarga de RAM y CPU.
En resumen, In-Chip ofrece un enorme potencial en términos de eficiencia para manejar, de forma flexible, fácilmente 5 terabytes de datos y más allá, aumentando la escala al optimizar el uso de los recursos disponibles, equilibrando el disco contra la memoria y la CPU. También se ajusta automáticamente a los volúmenes de datos al número de usuarios y cargas de trabajo que se están ejecutando.
Volvamos al inicio: ¿Problemas con el rendimiento de los datos? ¿Infraestructuras ajustadas? ¿Por qué deberías sufrir si hay soluciones eficientes? Llámanos y te explicaremos cuál es la respuesta más innovadora. Con Sisense y su modelo In-Chip technology haremos que tus problemas de rendimiento con las analíticas sea cosa del pasado.
¡Vamos!
Javier Irazazábal
Parapentex Data & Analytics Studio
CTO & Associate